Using compute power to iterate faster through ML experiments
How to scale up Machine Learning using AWS, Docker, WandB, and Python.
Using Compute Power to Iterate Faster Through ML Experiments
Bootstrap experiments and boost productivity with Python templates in the context of Machine Learning

I have created a Python template that makes running ML experiments on AWS convenient so you too can take advantage of massive cloud compute for your projects. This cuts down the experiment cycle time, allows you to batch multiple experiments together, and boosts overall productivity.
Motivation
Waiting for scripts to terminate is an absolute pet peeve of mine. Not only is it a waste of time but the constant context-switching is distracting and tiring. One grievous offender is the ML experiment, which lasts anywhere from a few minutes to a few days. A fixture of the development lifecycle, the ML experiment takes place any time you want to evaluate your model on a new set of hyperparameters (as in hyperparameter optimization), explore new features (feature selection), or try out a new model architecture. In a way, features and model architectures are simply glorified forms of hyperparameters. An ML experiment can always be thought of as tuning a constrained set of binary hyperparameters to maximize your evaluation metric.
Of course, you may have the discipline to go read Bishop the first time your 10-minute experiment is running. But after the tenth iteration, chances are experiment fatigue will kick in and you will zone out on reddit instead. Is there a way to, if not shorten the waiting time, at least batch multiple experiments together? The answer is yes.
The main ingredient to unlocking compute power for ML is parallelization. Interestingly, in the cloud you pay the same amount whether you rent out one server for 24 hours or 24 servers for one hour. In other words, by dividing your workload into 24 chunks and running them on commodity machines, you will get your results 24x faster for the same price! All of this works because hyperparameter tuning — a synonym for an ML experiment as we have seen — is embarassingly parallel by construction.
Getting started
Let’s put these ideas together and jump right in with the problem of predicting real estate prices using the Boston dataset. For the sake of simplicity, the experiment will consist of tuning a handful of XGBoost parameters like max_depth (see XGBoost docs) to maximize the performance of our model as measured by the MSE.
- Prerequisites
- Cookiecutter: Install cookiecutter with
$~ pip install cookiecutter - AWS region: This can be found in the top right corner of the AWS console eg. eu-central-1.
- wandb_key: You will have to create an account and copy the wandb key found here https://wandb.ai/authorize.
- The template: Finally, download the template with the following command:
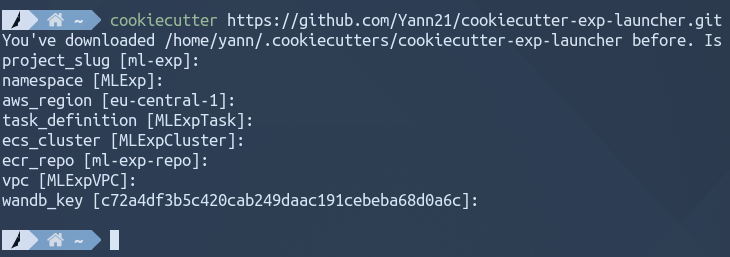
2. Adding your own code
- src/demo.py This file contains the code of your parametrized experiment as well as the input parameters at the top. In our case, it evaluates an XGBoost model on the Boston dataset.
- wandb/sweep.yaml The yaml file defines the range of value that will be explored. For this demonstration we have decided to run a grid search on 180 different hyperparameter combinations. There are a few other strategies than grid search like Bayesian optimization that you can explore here.
3. Executing your application$~ cd ml-exp/Initialize AWS resources (done only once)
$~ ./cli.py initBuild and push the Docker application to AWS
$~ ./cli.py dockerPull the trigger
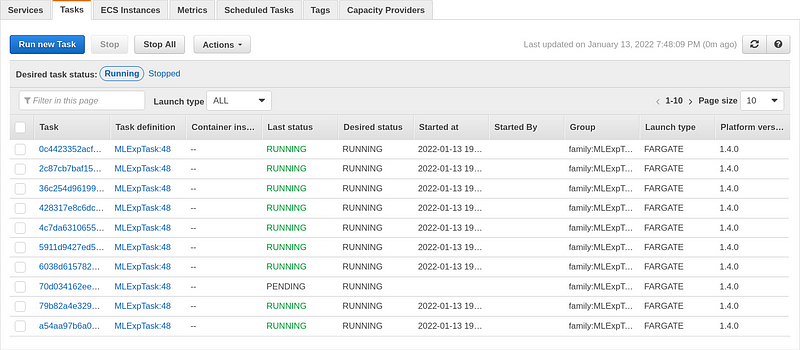
$~ ./cli.py run 20
At this point, you will have initialized the necessary resources on AWS and built the application into a Docker container which is running on 20 different servers.
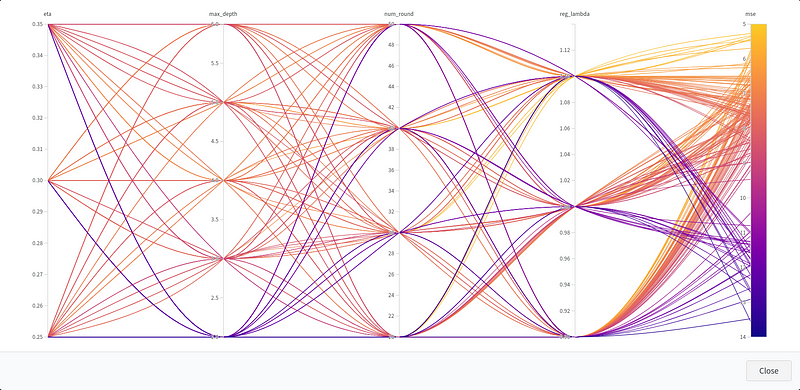
And voilà! The results will start trickling in to your wandb dashboard. You will be able to visualize your results, infer the right conclusions, and prepare the next round of experiments.
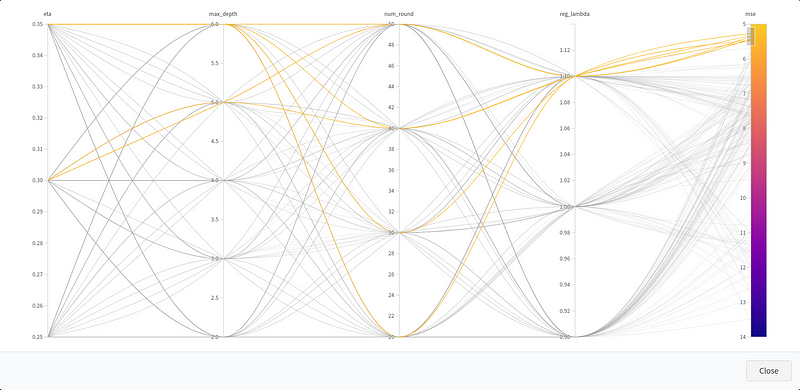
Under the hood, wandb takes care of coordinating the experiment. It injects hyperparameters to your fleet of containers, which run in parallel and independently of each other. After a hyperparameter is evaluated by an AWS container, wandb retrieves the result and aggregates everything into a parallel plot dashboard. Pretty cool?Don't forget to tear down your AWS resources when you're done
$~ ./cli.py clean
Conclusion
In summary, we have seen how it is possible to create a simple experiment, parametrize it with a yaml configuration file, and quickly evaluate its potential on a fleet of AWS containers. We got the best of both worlds by making the experiment faster through parallelization at scale, and simpler by batching multiple parameters together to the great delight of mono-taskers like me.
If you happen to need more firepower, I would recommend you check out the full-fledged lightning-hydra-template repo, which comes with many more features.
You can find the source code of my template here or go back and start running your own application in the cloud.
Thanks a lot for reading. I am looking forward to your valuable feedback!



